
Gotta catch them all
Introduction
When data becomes high-dimensional, the inherent relational structure between the variables can sometimes become unclear or indistinct. One, might want to find clusters for numerous amounts of reasons - me, I want to use it to better understand my childhood. To be more specific, I will be using clustering to highlight different groupings of pokemon. The results of this analysis can then retrospectively be applied to a younger me having to choose which pokemon I catch and keep, or perhaps which I must rather use in battle to gain experience points. The clusters should help me identify groupings of pokemons that assimilate with my style of play, be it catching pokemon who are specialist of their type, strong attackers, survivalist who have good defensive capabilities or pokemon who have the potential to become great as soon as they evolve.
This train of thought (aka hypothesis) will carry through to the analysis when number of cluster and inference needs to be conducted.
About clustering techniques
Within the CRM field, a common practice is to segment client data in order to identify certain clusters of customers, users or products. The first question that I asked myself when I first encountered this technique was: “How usefull can this really be when there is no quantitative measure which dictates the number of clusters”. The answer to this question became quite clear to me when I encountered a dataset of 8000 variables.
Clustering lies within the field of data-reduction, and has the intention to uncover cohesive subgroups of observations within a very large dataset where inference aren’t always clear from face value - i.e an Excel pivot table isn’t going to cut it. Clustering is not only used within marketing, but is applied in biology, behavioural sciences, economics and medical research. The application of cluster analysis in the medical sciences interest me, as they use this technique to help catalog gene-expression patters which were obtained from DNA microarray data. Very cool application of this statistical technique. Without clustering, this task would become almost impossible due to the large amount of information.
Clustering can primarily be divided up in two techniques:
- Hierarchical Agglomerative methods
- Partitioning clustering
Hierarchical agglomerative clustering works from a bottom up approach where at the beginning, each observation is in its own cluster. From this clusters are combined into larger clusters, 2 at a time, until all the cluster have essentially been merged into one big cluster. With partitioning, one will specify K cluster which are sought after. Then the algorithm will essentially start by picking randomly dividing observations into clusters, assessing similarity, reshuffle, asses again and keep doing this until cohesive clusters are formed.
There is a lot of different techniques, but for the rest of this exploration into the topic, I will be using hierarchical agglomerative clustering (hclust) as my choice of clustering algorithm.
Now, the question is: “How are the observations linked to form these clusters?”. In hclust the most popular techniques are:
- Single linkage: Shortest distance between a point in one cluster and a point in the other cluster.
- Complete linkage: Longest distance between a point in one cluster and a point in the other cluster.
- Average linkage: Average distance between each point in one cluster and each point in the other cluster (also called UPGMA [unweighted pair group mean averaging])
- Centroid: Distance between the centroids (vector of variable means) of the two clusters. For a single observation, the centroid is the variable’s values.
- Ward’s Method: The ANOVA sum of squares between the two clusters added up over all the variables.
You are probably asking - what distance are you talking about here? We will use the dist() function in R to calculate the euclidean distance:
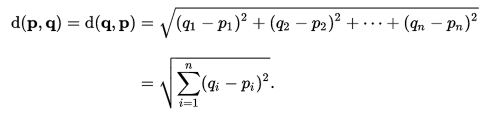
Euclidean dit
where q and p are the observations and N is the number of variables. Easy enough right? I will be using ward’s method to cluster my objects as it is the default setting for Hierarchical agglomerative clustering for the HCPC function in library(FactoMineR)
Lets go catch our pokemon
To collect the data on all the first generation pokemon, I employ Hadley Wickam’s rvest package. I find it very intuitive and can handle all of my needs in collecting and extracting the data from a pokemon wiki. I will grab all the Pokemon up until to Gen II, which constitutes 251 individuals. I did find the website structure a bit of a pain as each pokemon had very different looking web pages. But, with some manual hacking, I eventually got the data in a nice format.
The cleaned data looks as follows:
library(ggplot2)
library(FactoMineR)
all_pokemon <- download.file("https://raw.githubusercontent.com/Eighty20/eighty20.github.io/master/_rmd/Post_data/All_pokemon.csv", destfile = "/tmp/Pokemon.csv", method = "curl")
all_pokemon <- read.csv("/tmp/Pokemon.csv", stringsAsFactors = F)
cat("Dimensions for pokemon data is :",dim(all_pokemon))## Dimensions for pokemon data is : 251 15head(all_pokemon)## Nat Pokemon HP Atk Def SA SD Spd Total Type.I Type.II Gender
## 1 1 Bulbasaur 45 49 49 65 65 45 318 Grass Poison M (87.5%)
## 2 2 Ivysaur 60 62 63 80 80 60 405 Grass Poison M (87.5%)
## 3 3 Venusaur 80 82 83 100 100 80 525 Grass Poison M (87.5%)
## 4 4 Charmander 39 52 43 60 50 65 309 Fire M (87.5%)
## 5 5 Charmeleon 58 64 58 80 65 80 405 Fire M (87.5%)
## 6 6 Charizard 78 84 78 109 85 100 534 Fire Flying M (87.5%)
## Evolves.From lvl_up Evolves.Into
## 1 -- Lv. 16 Ivysaur
## 2 Bulbasaur Lv. 32 Venusaur
## 3 Ivysaur -- --
## 4 -- Lv. 16 Charmeleon
## 5 Charmander Lv. 36 Charizard
## 6 Charmeleon -- --For those of you who know pokemon well, will also know that certain pokemon have only one evolution stage. We remove them in order to not intervere with our clustering at a later stage.
Evo_none <- all_pokemon[which(all_pokemon$Evolves.From == "--" & all_pokemon$Evolves.Into=="--"), ]The following pokemon were removed from the dataset: Farfetch’d, Kangaskhan, Pinsir, Tauros, Lapras, Ditto, Aerodactyl, Articuno, Zapdos, Moltres, Mewtwo, Mew, Unown, Girafarig, Dunsparce, Qwilfish, Shuckle, Heracross, Corsola, Delibird, Skarmory, Stantler, Smeargle, Miltank, Raikou, Entei, Suicune, Lugia, Ho-oh, Celebi
The next step was to aggregate all the stage 2 statistics for the stage 1 evolution pokemon. This results in a nice wide dataset of variables we are able to use in our clustering. I am hoping to extract some sense of strenghts in pokemon, not only by their stage 1 statistics, but also perhaps their potential to become awesome assets later. One hopeful example of this would be everyone’s favourite: magikarp.
Evo_1 <- all_pokemon[which(all_pokemon$Evolves.From=="--" & all_pokemon$Evolves.Into!="--"), ]
Evo_2 <- all_pokemon[which(all_pokemon$Evolves.From!="--"), ]
##### Housekeeping - organise data into cluster format #####
Matched_pokemon <- merge(Evo_1,
Evo_2[,!names(Evo_2) %in% c('Evolves.Into')],
by.x = "Evolves.Into",
by.y = "Pokemon",
all.x = T,
suffixes = c(".lv1",".lv2"))
#Create level of evolution variable
Matched_pokemon$lvl_up.lv1 <- as.integer(gsub("[^0-9]+","", Matched_pokemon$lvl_up.lv1))
#Finalize complete set of pokemon
Matched_pokemon <- Matched_pokemon[complete.cases(Matched_pokemon), ]
pokemon <- Matched_pokemon$Pokemon
#Correct for Nidoran
pokemon[grep("Nido",pokemon)] <- c("Nidoran(F)","Nidoran(M)")
selected_var<-c("HP.lv1","HP.lv2",
"Atk.lv1","Atk.lv2",
"Def.lv1","Def.lv2",
"SA.lv1","SA.lv2",
"SD.lv1","SD.lv2",
"Spd.lv1","Spd.lv2",
"Total.lv1","Total.lv2",
"Type.I.lv1","lvl_up.lv1")
Matched_pokemon <- Matched_pokemon[ ,names(Matched_pokemon)%in%selected_var]
row.names(Matched_pokemon) <- pokemonThe data has been constructed to capture characteristics of a specific pokemon at both the first and second level of evolution. It is these variables that we will be using in our clustering. The total column acts as a general indicator of pokemon’s attributes:
| HP.lv1 | Atk.lv1 | Def.lv1 | SA.lv1 | SD.lv1 | Spd.lv1 | Total.lv1 | |
|---|---|---|---|---|---|---|---|
| Ekans | 30 | 60 | 44 | 40 | 54 | 55 | 283 |
| Spinarak | 40 | 60 | 40 | 40 | 40 | 30 | 250 |
| Chikorita | 45 | 49 | 65 | 49 | 65 | 45 | 318 |
| Charmander | 39 | 52 | 43 | 60 | 50 | 65 | 309 |
| Totodile | 50 | 65 | 64 | 44 | 48 | 43 | 314 |
| Seel | 65 | 45 | 55 | 45 | 70 | 45 | 325 |
| Type.I.lv1 | lvl_up.lv1 | HP.lv2 | Atk.lv2 | Def.lv2 | SA.lv2 | SD.lv2 | |
|---|---|---|---|---|---|---|---|
| Ekans | Poison | 22 | 60 | 85 | 69 | 65 | 79 |
| Spinarak | Bug | 22 | 70 | 90 | 70 | 60 | 60 |
| Chikorita | Grass | 16 | 60 | 62 | 80 | 63 | 80 |
| Charmander | Fire | 16 | 58 | 64 | 58 | 80 | 65 |
| Totodile | Water | 18 | 65 | 80 | 80 | 59 | 63 |
| Seel | Water | 34 | 90 | 70 | 80 | 70 | 95 |
| Spd.lv2 | Total.lv2 | |
|---|---|---|
| Ekans | 80 | 438 |
| Spinarak | 40 | 390 |
| Chikorita | 69 | 414 |
| Charmander | 80 | 405 |
| Totodile | 58 | 405 |
| Seel | 70 | 475 |
For those curious to see the pokemon which ended up in our dataset. Here they are:
## [1] "Ekans" "Spinarak" "Chikorita" "Charmander" "Totodile"
## [6] "Seel" "Doduo" "Phanpy" "Dratini" "Diglett"
## [11] "Voltorb" "Spearow" "Pineco" "Sentret" "Oddish"
## [16] "Zubat" "Psyduck" "Snubbull" "Magikarp" "Gastly"
## [21] "Houndour" "Drowzee" "Bulbasaur" "Smoochum" "Kabuto"
## [26] "Abra" "Weedle" "Krabby" "Chinchou" "Ledyba"
## [31] "Machop" "Slugma" "Magnemite" "Cubone" "Caterpie"
## [36] "Grimer" "Nidoran(F)" "Nidoran(M)" "Hoothoot" "Remoraid"
## [41] "Omanyte" "Paras" "Meowth" "Pidgey" "Swinub"
## [46] "Poliwag" "Mankey" "Larvitar" "Wooper" "Cyndaquil"
## [51] "Ponyta" "Rhyhorn" "Sandshrew" "Horsea" "Goldeen"
## [56] "Hoppip" "Slowpoke" "Tentacool" "Teddiursa" "Squirtle"
## [61] "Bellsprout" "Koffing" "Natu"One of the interesting variables that forms part of the data is the crucial question every trainer asks himself when catching pokemon - which types are the strongest? For each of my ~60 pokemon I use a boxplot to evaluate the relative strenght of a type. The data was normalized per level of evolution to ease plotting and interpretation. 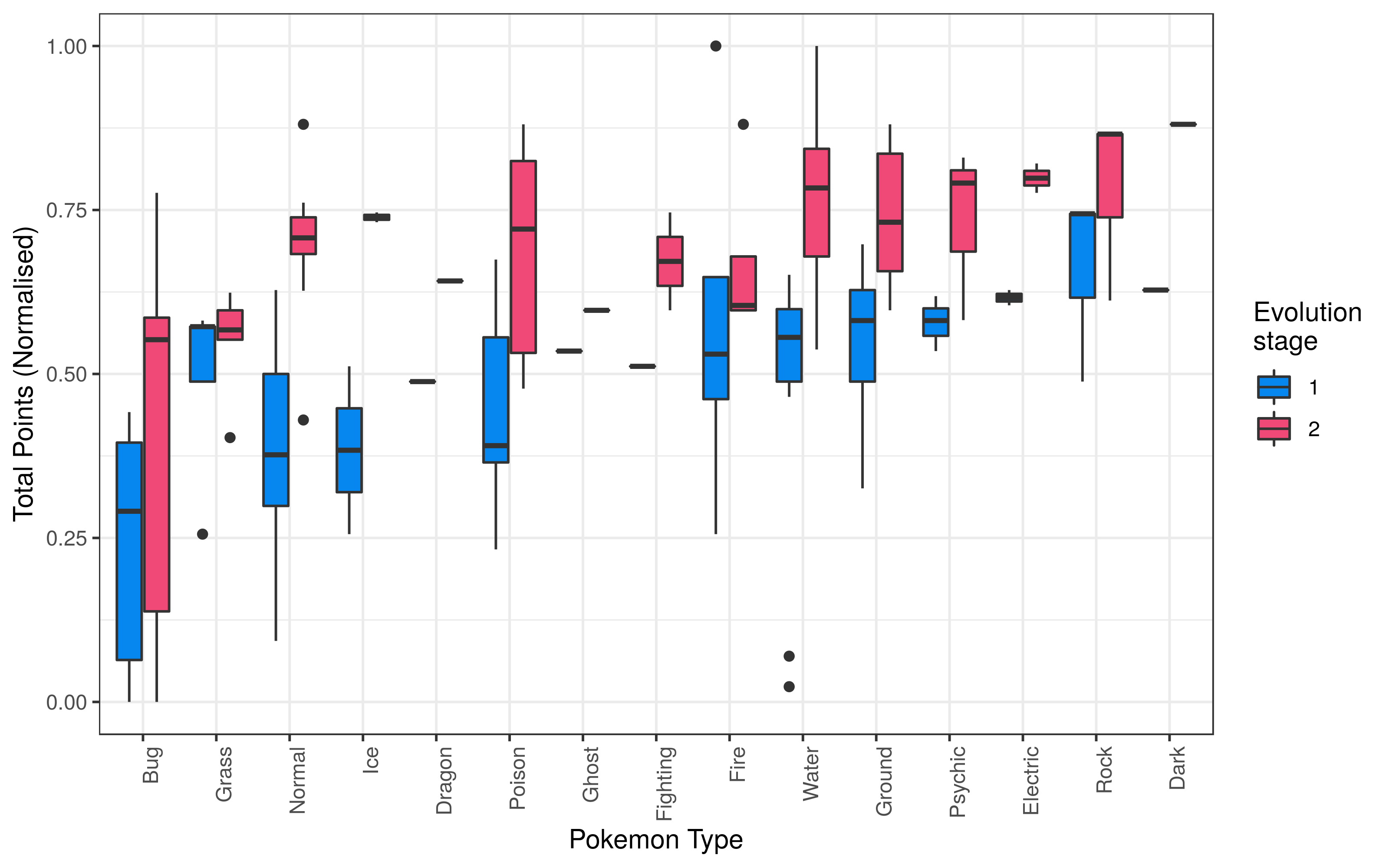 Good old bug pokemons don’t catch a break, with the median
Good old bug pokemons don’t catch a break, with the median total points being the lowest in both stages of evolution. For Normal, Poison and Water types, there seems to be a definite advantage to evolve in order to ‘up’ the overall statistics. An interesting type to evaluate is the Fire type pokemon. In the first stage of evolution this type of pokemon seems to have an overall advantage, but once the pokemon starts evolving, the advantage dissipates.
One of the concerns I had was the class imbalance that might be present in the pokemon type. 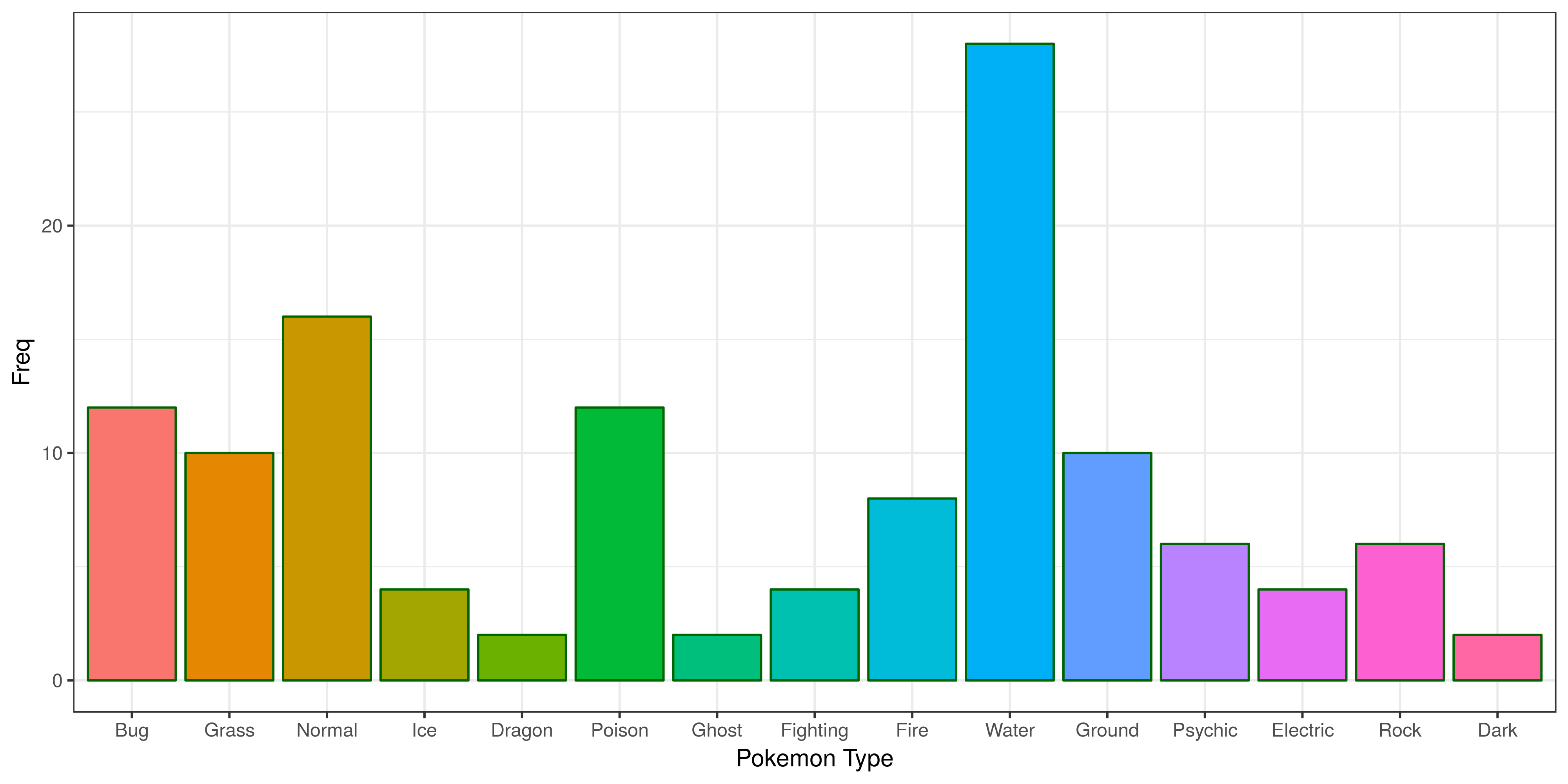 The graph clearly points this out, so instead of adding the pokemon types into the analysis, they will be included as supplementary variable.
The graph clearly points this out, so instead of adding the pokemon types into the analysis, they will be included as supplementary variable.
Going Prof Elm and analysing pokemon
If you don’t know who Prof Elm is, this link should help. To start our exploration into the pokemon dataset, we will conduct a multiple factor analysis. I find the flexibility of this function being able to conduct MCA and PCA in one go very helpful. It also has incredible plotting functions that helps to visually analyse your data.
Matched_pokemon$Type.I.lv1 <- as.factor(Matched_pokemon$Type.I.lv1)
res <- MFA(Matched_pokemon,group = c(6,1,1,7,1),type=c(rep("s",2),"n",rep("s",2)),
ncp=5,name.group = c("Lvl1","ToT1","Type","Lvl2","ToT2"),
num.group.sup = c(2,3,5),graph = F)
plot(res,choix = "var", habillage = "group", cex=0.8, shadow = T)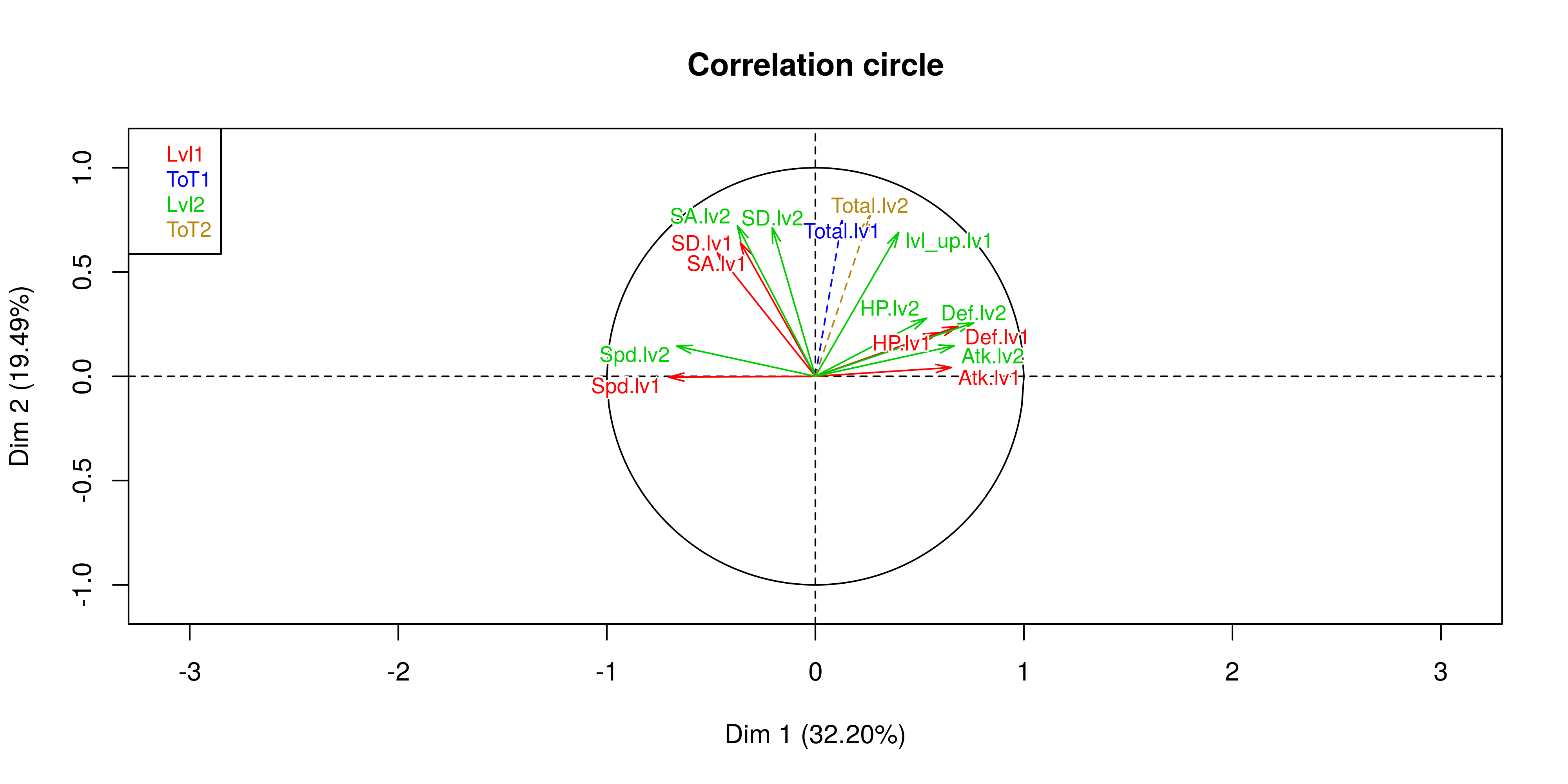 Here we see that there is a definite inverse relationship between the speed of a Pokemon and its attack statistics. I find the relationship between special attack and normal attack interesting. It would seem that you either specialise or defualt to having a strong overall attack.
Here we see that there is a definite inverse relationship between the speed of a Pokemon and its attack statistics. I find the relationship between special attack and normal attack interesting. It would seem that you either specialise or defualt to having a strong overall attack.
The first thing to look at is the dispersion of the pokemon types to see how correlation all the pokemons are given their type. 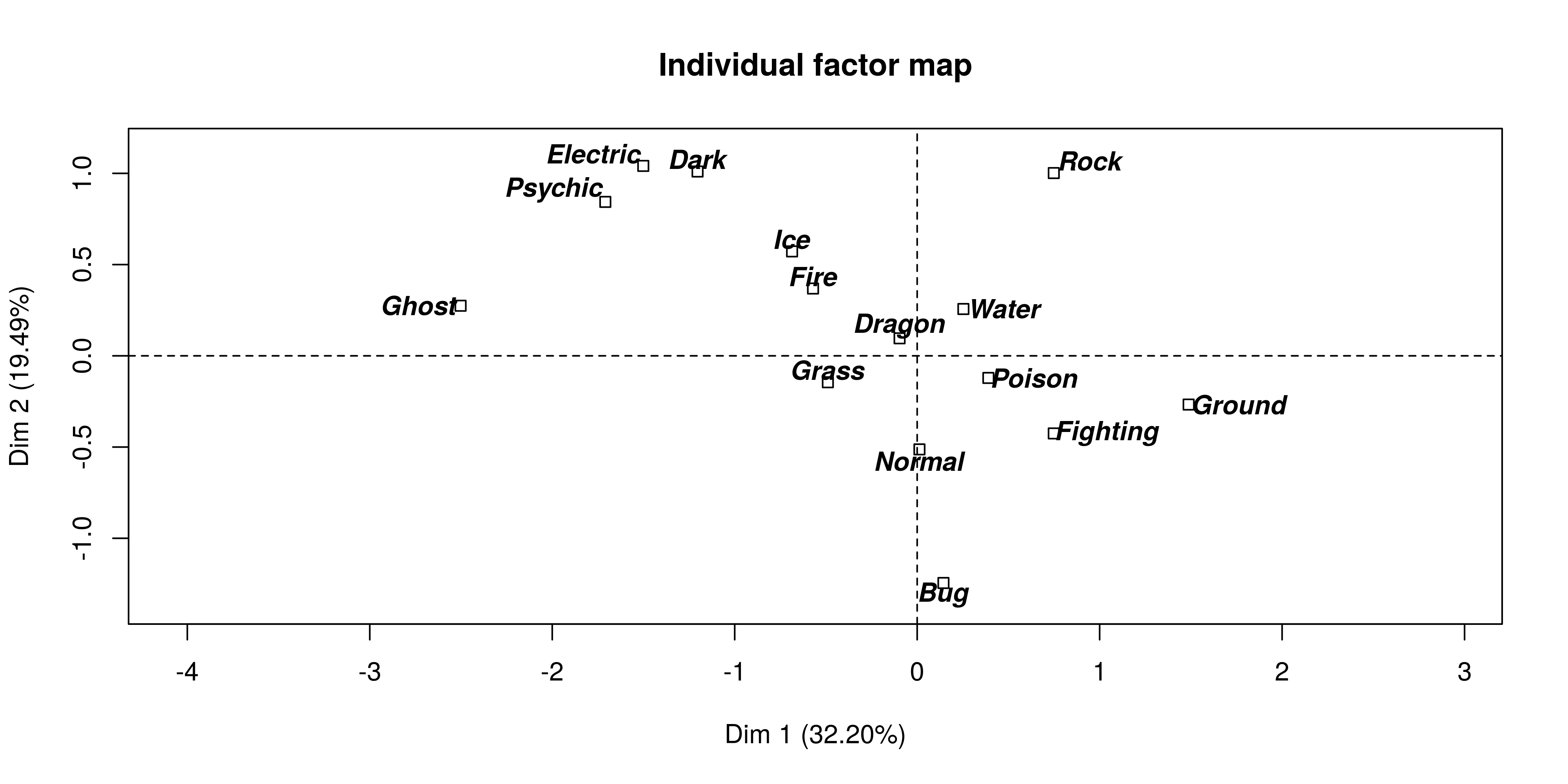 It would seem that Ghost, Psyhic and Electric pokemon have different characteristics than those of Ground, Fighting and Bug for instance.
It would seem that Ghost, Psyhic and Electric pokemon have different characteristics than those of Ground, Fighting and Bug for instance.
Given these factor groups, next it would be interesting to see which of the pokemon had the highest contribution to the construction dimension (Contribution 10). I also want to see the highest quality of representation (cos2>0.6). The cos squared, indicates the contribution of a component to the squared distance of the observation to the origin. i.e cos squared is an important contributor to find the components that are important to interpret both active and supplementary observations, Abdi H, 2010. 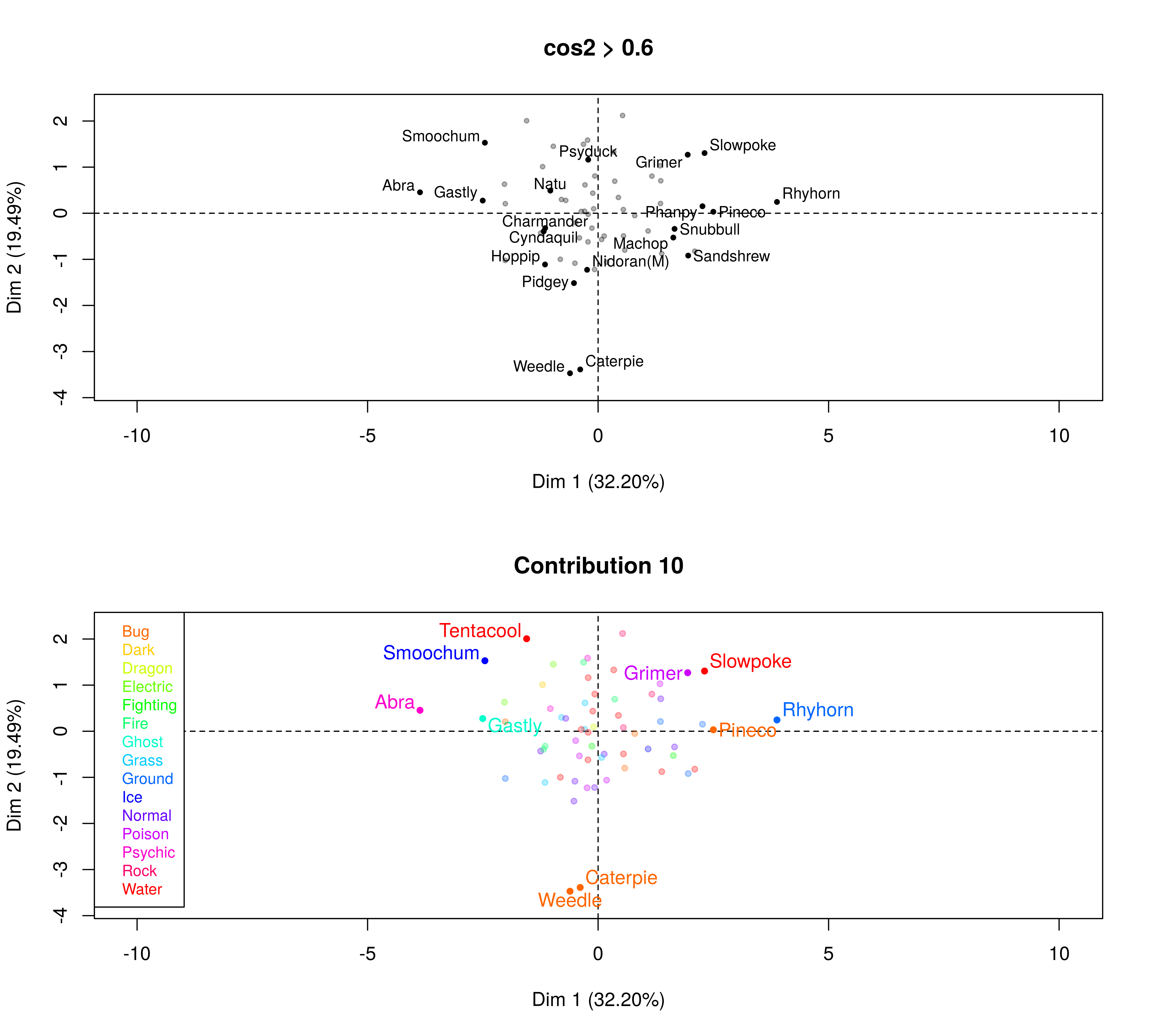
Now that we have a clearer understanding of the data, its finally time to conduct the exciting cluster analysis on the data. With the MFA function, this is easily done by plugging the results directly into a hierarchical clustering algorithm. I decided to cut the tree to get 4 clusters in the end. Felt that these represented the different facets of pokemon quite well.
res.hcpc <- HCPC(res, nb.clust=4, consol=TRUE, iter.max=10, min=3,
max=NULL, metric="euclidean", method="ward", order=TRUE,
graph.scale="inertia", nb.par=5, graph=F, proba=0.05,
cluster.CA="rows",kk=Inf)Here we can see a 3D representation of the tree that was build: 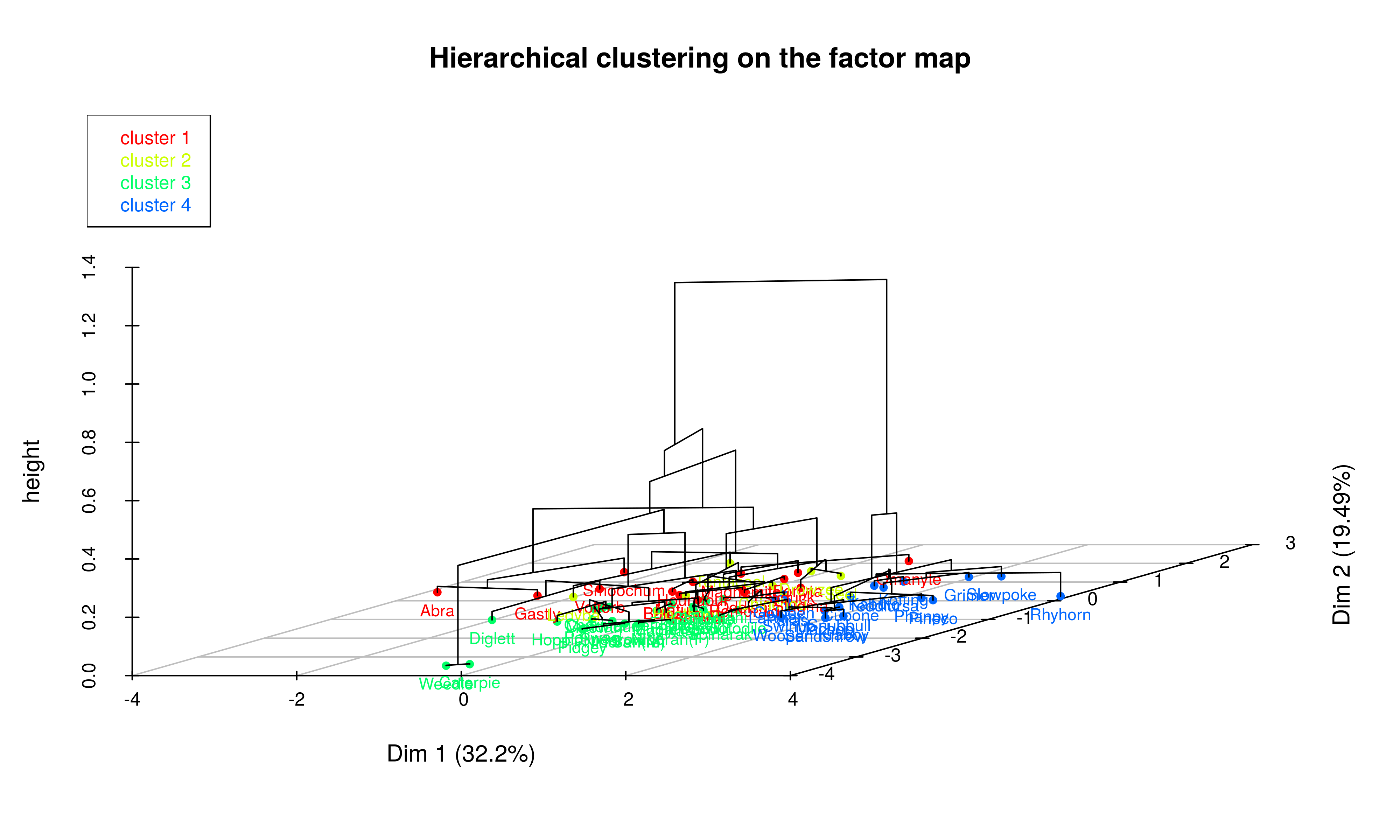
I wanted to see the type dispersion among the clusters, perhaps hoping to see a coherent split of types among the clusters…
| 1 | 2 | 3 | 4 | |
|---|---|---|---|---|
| Bug | 0 | 1 | 3 | 2 |
| Dark | 1 | 0 | 0 | 0 |
| Dragon | 0 | 0 | 1 | 0 |
| Electric | 2 | 0 | 0 | 0 |
| Fighting | 0 | 0 | 1 | 1 |
| Fire | 2 | 0 | 2 | 0 |
| Ghost | 1 | 0 | 0 | 0 |
| Grass | 2 | 0 | 3 | 0 |
| Ground | 0 | 0 | 1 | 4 |
| Ice | 1 | 0 | 0 | 1 |
| Normal | 0 | 1 | 5 | 2 |
| Poison | 0 | 0 | 4 | 2 |
| Psychic | 2 | 1 | 0 | 0 |
| Rock | 1 | 0 | 0 | 2 |
| Water | 3 | 3 | 4 | 4 |
| Sum | 15 | 6 | 24 | 18 |
Now comes the interesting bit, dissecting the data to see which pokemon clustered together and why they were thrown into the same cluster.
Cluster 1
Ok, so the pokemon that ended up in cluster 1 was: Voltorb, Oddish, Psyduck, Gastly, Houndour, Bulbasaur, Smoochum, Abra, Slugma, Magnemite, Remoraid, Omanyte, Ponyta, Horsea, Natu. This is quite an odd bunch if you know pokemon well. So, what was it that made them cluster together?
| Stat | v.test | Mean.in.category | Overall.mean | p.value |
|---|---|---|---|---|
| SA.lv1 | 6.2 | 77 | 49 | 0 |
| SA.lv2 | 5.9 | 99 | 71 | 0 |
| Total.lv1 | 2.5 | 320 | 297 | 0.01 |
| Spd.lv1 | 2 | 61 | 52 | 0.05 |
| HP.lv1 | -2 | 39 | 46 | 0.04 |
| Atk.lv1 | -2.1 | 45 | 54 | 0.04 |
| Atk.lv2 | -2.1 | 67 | 79 | 0.03 |
| HP.lv2 | -2.3 | 61 | 70 | 0.02 |
These Pokemon are specialist in special attacking moves. With the mean attack stat being almost 1/4 higher than the mean of all the other pokemon. These pokemon should be used when there is a type advantage!
Cluster 2
Moving onto cluster 2: Seel, Drowzee, Chinchou, Ledyba, Hoothoot, Tentacool.
| Stat | v.test | Mean.in.category | Overall.mean | p.value |
|---|---|---|---|---|
| SD.lv1 | 4.8 | 75 | 46 | 0 |
| SD.lv2 | 4.5 | 102 | 70 | 0 |
| HP.lv2 | 2.8 | 89 | 70 | 0 |
| Atk.lv2 | -2 | 59 | 79 | 0.05 |
| Atk.lv1 | -2.4 | 37 | 54 | 0.02 |
Although these pokemon have defensive capabilities, these capabilities are more pronounced than what we saw in cluster 1 where the individuals had a small significant advantage in a specialized situation.
Cluster 3
This cluster was the biggest with 24 Pokemon ending up in this category. The pokemon that forms part of this cluster is: Ekans, Spinarak, Chikorita, Charmander, Totodile, Doduo, Dratini, Diglett, Spearow, Sentret, Zubat, Magikarp, Weedle, Caterpie, Nidoran(F), Nidoran(M), Meowth, Pidgey, Poliwag, Mankey, Cyndaquil, Hoppip, Squirtle, Bellsprout.
| Stat | v.test | Mean.in.category | Overall.mean | p.value |
|---|---|---|---|---|
| SD.lv1 | -2.1 | 41 | 46 | 0.04 |
| Def.lv1 | -2.5 | 42 | 50 | 0.01 |
| HP.lv2 | -2.5 | 63 | 70 | 0.01 |
| HP.lv1 | -2.6 | 39 | 46 | 0.01 |
| SA.lv1 | -2.7 | 40 | 49 | 0.01 |
| SD.lv2 | -2.8 | 62 | 70 | 0 |
| Def.lv2 | -3 | 64 | 75 | 0 |
| SA.lv2 | -3.5 | 58 | 71 | 0 |
| Total.lv1 | -3.8 | 272 | 297 | 0 |
| Total.lv2 | -3.9 | 396 | 434 | 0 |
| lvl_up.lv1 | -4.5 | 20 | 25 | 0 |
It would seem that these pokemon underscore on all statistics and should probably we avoided as strategic investments in your lineup.
Cluster 4
The last group that was identified were Pokemon that are all-rounders. Phanpy, Pineco, Snubbull, Kabuto, Krabby, Machop, Cubone, Grimer, Paras, Swinub, Larvitar, Wooper, Rhyhorn, Sandshrew, Goldeen, Slowpoke, Teddiursa, Koffing - have overall statistics which are higher than average, but does not specialize in any of the type specific advantages that exist in the Pokemon games.
| Stat | v.test | Mean.in.category | Overall.mean | p.value |
|---|---|---|---|---|
| Atk.lv2 | 4.6 | 102 | 79 | 0 |
| Def.lv2 | 4.5 | 96 | 75 | 0 |
| Atk.lv1 | 4.3 | 70 | 54 | 0 |
| Def.lv1 | 4.3 | 68 | 50 | 0 |
| HP.lv1 | 3.5 | 56 | 46 | 0 |
| lvl_up.lv1 | 3.1 | 30 | 25 | 0 |
| HP.lv2 | 3 | 81 | 70 | 0 |
| Total.lv2 | 2.1 | 460 | 434 | 0.03 |
| SD.lv1 | -2 | 40 | 46 | 0.05 |
| SA.lv1 | -2.6 | 38 | 49 | 0.01 |
| Spd.lv2 | -3.8 | 51 | 70 | 0 |
| Spd.lv1 | -4 | 35 | 52 | 0 |
Paragons of the clusters
One of the nicest outputs of HCPC is the listed paragons per group. These paragons can be seen as the poster-child representative of each cluster as they lie closest to the center of the cluster:
Cluster 1:
| Natu | Psyduck | Houndour | Remoraid | Bulbasaur |
|---|---|---|---|---|
| 0.67 | 1.2 | 1.3 | 1.3 | 1.4 |
Cluster 2:
| Drowzee | Hoothoot | Seel | Tentacool | Chinchou |
|---|---|---|---|---|
| 0.88 | 1.1 | 1.2 | 1.7 | 1.7 |
Cluster 3:
| Nidoran(M) | Zubat | Pidgey | Poliwag | Sentret |
|---|---|---|---|---|
| 0.57 | 0.65 | 0.71 | 0.83 | 0.89 |
Cluster 4:
| Snubbull | Phanpy | Machop | Larvitar | Swinub |
|---|---|---|---|---|
| 1 | 1.1 | 1.1 | 1.1 | 1.2 |
The output of the HCPC also allows us to see the individuals which are the most distance from all the other cluster. For brevity, ill leave this table out of this post. These most distant individuals are usually outliers which end up in the group to which it relates (relatively) the closest.
Conclusion
This post explored cluster analysis, or formally put, a tool in which a multivariate dataset can be explored and eventually be divided into subgroups of similar data based on some kind of proximity estimate. I used Pokemon data as I found it to be an interesting dataset to apply this kind of technique. I must say, that the FactoMineR library helps a lot in facilitating the clustering process once your dataset is in proper format. It takes you through a natural progression of clustering application with a lot of flexibility available to the user to tune the analysis to his/hers needs. I especially like the MFA function where both PCA and MCA can be integrated into a concise function.
In terms of the results, I think it would be interesting to further delve into type combinations within the group in order to have the strongest Pokemon along with a type advantage. But we will leave this for another day…