
Design and Analysis of Experiments with R
Introduction
This document will cover in depth the use of DoE experiments in R! We will focus our attention to measuring treatment effects, not variances.
Based on the work:
Lawson, John. Design and Analysis of Experiments with R. Chapman and Hall/CRC, 20141217. VitalBook file.

Definitions
Experiment (also called a Run) is an action where the experimenter changes at least one of the variables being studied and then observes the effect of his or her actions(s). Note the passive collection of observational data is not experimentation.
Experimental Unit is the item under study upon which something is changed. This could be raw materials, human subjects, or just a point in time.
Sub-Sample, Sub-Unit, or Observational Unit When the experimental unit is split, after the action has been taken upon it, this is called a sub-sample or sub-unit. Sometimes it is only possible to measure a characteristic separately for each sub-unit; for that reason they are often called observational units. Measurements on sub-samples, or sub-units of the same experimental unit, are usually correlated and should be averaged before analysis of data rather than being treated as independent outcomes. When sub-units can be considered independent and there is interest in determining the variance in sub-sample measurements, while not confusing the F-tests on the treatment factors, the mixed model described in Section 5.8 should be used instead of simply averaging the sub-samples.
Independent Variable (Factor or Treatment Factor) is one of the variables under study that is being controlled at or near some target value, or level, during any given experiment. The level is being changed in some systematic way from run to run in order to determine what effect it has on the response(s).
Background Variable (also called a Lurking Variable) is a variable that the experimenter is unaware of or cannot control, and which could have an effect on the outcome of the experiment. In a well-planned experimental design, the effect of these lurking variables should balance out so as to not alter the conclusion of a study.
Dependent Variable (or the Response denoted by Y) is the characteristic of the experimental unit that is measured after each experiment or run. The magnitude of the response depends upon the settings of the independent variables or factors and lurking variables.
Effect is the change in the response that is caused by a change in a factor or independent variable. After the runs in an experimental design are conducted, the effect can be estimated by calculating it from the observed response data. This estimate is called the calculated effect. Before the experiments are ever conducted, the researcher may know how large the effect should be to have practical importance. This is called a practical effect or the size of a practical effect.
Replicate runs are two or more experiments conducted with the same settings of the factors or independent variables, but using different experimental units. The measured dependent variable may differ among replicate runs due to changes in lurking variables and inherent differences in experimental units.
Duplicates refer to duplicate measurements of the same experimental unit from one run or experiment. The measured dependent variable may vary among duplicates due to measurement error, but in the analysis of data these duplicate measurements should be averaged and not treated as separate responses.
Experimental Design is a collection of experiments or runs that is planned in advance of the actual execution. The particular runs selected in an experimental design will depend upon the purpose of the design.
Confounded Factors arise when each change an experimenter makes for one factor, between runs, is coupled with an identical change to another factor. In this situation it is impossible to determine which factor causes any observed changes in the response or dependent variable.
Biased Factor results when an experimenter makes changes to an independent variable at the precise time when changes in background or lurking variables occur. When a factor is biased it is impossible to determine if the resulting changes to the response were caused by changes in the factor or by changes in other background or lurking variables.
Experimental Error is the difference between the observed response for a particular experiment and the long run average of all experiments conducted at the same settings of the independent variables or factors. The fact that it is called “error” should not lead one to assume that it is a mistake or blunder. Experimental errors are not all equal to zero because background or lurking variables cause them to change from run to run. Experimental errors can be broadly classified into two types: bias error and random error. Bias error tends to remain constant or change in a consistent pattern over the runs in an experimental design, while random error changes from one experiment to another in an unpredictable manner and average to be zero. The variance of random experimental errors can be obtained by including replicate runs in an experimental design.
Condensed theory
DoE is used to distinguish between correlation and causality in a way that is cost efficient and accounts for most confounding effects and lurker effects.
Sequential strategies are used to determine what factors are most influencial and after that the changes in factors are quantified until finally optimal operating conditions are determined (most appropriate factor states to accomplish maximum treatment effect)
DoE Workflow
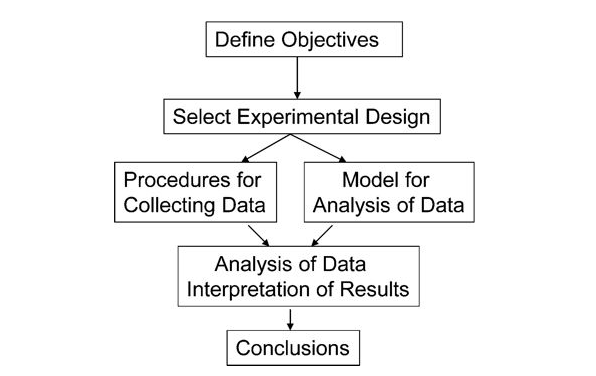 An effective experimental design will ensure the following:
An effective experimental design will ensure the following:
- A clear objective
- An appropriate design plan that gaurantees unconfounded and unbiased factor effects
- A plan for data collection to enable estimation of variance and experimental error
- A stipulation to collect enough data to satisfy the objectives
In order to achieve this we must:
- Define objectives
- identify experimental units
- Define a meaningful and measurable respnse or dependent variable
- List the independent and lurking vbariables
- Run pilot tests
- Make a flow diagram of the experimental procedure
- Choose the experimental design
- Determine number of replicants
- Randomize the experimental conditions to experimental units
- Describe a method for data analysis with tested dummy data
- Timetable and budget for resources
In particular it’s important to note that the time we have to run the experiment and the cost budget for the experiment will heavily impact the type of experimental design
When to use which design
Let’s summarise the theory to understand when we should use which experimental design:
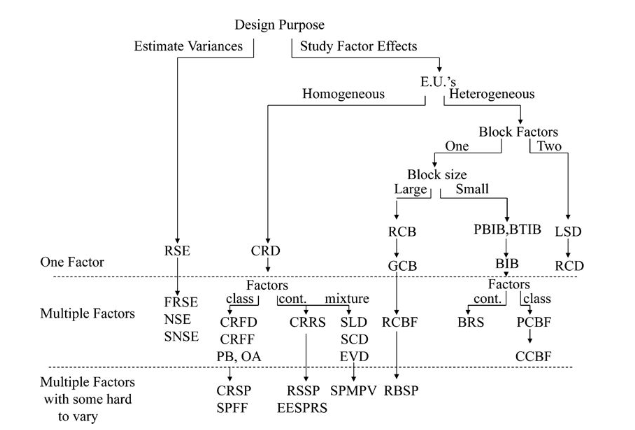
Clearly our very first split depends on what we wish to investigate, the variances or the effects of different factors.
Design Name Acronym Index
RSE - random sampling experiment
FRSE - factorial random sampling experiment
NSE - nested sampling experiment
SNSE - staggered nested sampling experiment
CRD - completely randomized design
CRFD - completely randomized factorial design
CRFF - completely randomized fractional factorial
PB - Plackett-Burman design
OA - orthogonal array design
CRSP - completely randomized split plot
RSSP - response surface split plot
EESPRS - equivalent estimation split-plot response surface
SLD - simplex lattice design
SCD - simplex centroid design
EVD - extreme vertices design
SPMPV - split-plot mixture process variable design
RCB - randomized complete block
GCB - generalized complete block
RCBF - randomized complete block factorial
RBSP - randomized block split plot
PBIB - partially balanced incomplete block
BTIB - balanced treatment incomplete block
BIB - balance incomplete block
BRS - blocked response surface
PCBF - partially confounded blocked factorial
CCBF - completely confounded blocked factorial
LSD - Latin-square design
RCD - row-column design
Study factor effects
We start off with the objective of studying factor effects on treatment response. We will illustrate the basic workflows using a simple 1 factor CRD with 1 response.
Completely randomized design (CRD)
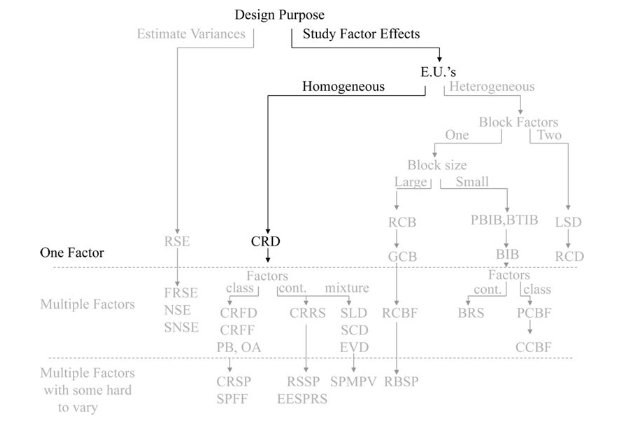
In completely randomized designs we consider only a single factor. For each possible state of this factor we have a treatment or group. The total number of experimental units n is equal to the number of treatments * the number of replications in of each treatment.
Replications are vital!
Without replications we couldn’t tell if the treatment effect was real or due to random manifistation of unmeasured effects.
Remember:
By randomly assigning treatments and replications we balance out the effects we are not aware of (law of large numbers fighting off lurker effects). We therefore assume any affects we do not account for are equally distributed accross treatments on average.
Sub-samples are not replicates!
Having two independant tasters taste/rate the same cake does not mean you have two replicates of that particular cake’s treatment.
Example
Bread dough experiment
Test bread rise height caused by factor time:
We test 3 values for time with 4 replicates each (12 experimental units of 3 treatments with 4 replicates)
set.seed(234789)
f <- factor(rep(c(35,40,45),each = 4))
randomized_times <- sample(f,12)
allocation <- 1:12
design <- data.frame(allocated_loaf = allocation, time = randomized_times)
design## allocated_loaf time
## 1 1 40
## 2 2 45
## 3 3 35
## 4 4 40
## 5 5 40
## 6 6 45
## 7 7 45
## 8 8 45
## 9 9 35
## 10 10 40
## 11 11 35
## 12 12 35Linear model used for CRD inference
Obviously we are only making inference about the mean effect within each treatment given the replications:
Cell mean model
A more useful representation:
Effects model
This formulation is more useful because is interpreted as the difference of the mean within treatment and the overall average.
If the design is executed properly the log likelihood function will be maximised if we minimise the sum of squares of residuals (linear regression).
BUT in R the lm() function will omit the first factor and derive coefficients relative to :
bread_example <- daewr::bread
bread_example %>% lm(formula = height~time) %>% summary##
## Call:
## lm(formula = height ~ time, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.812 -1.141 0.000 1.266 2.250
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 5.4375 0.7655 7.104 5.65e-05 ***
## time40 2.8125 1.0825 2.598 0.0288 *
## time45 2.8750 1.0825 2.656 0.0262 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.531 on 9 degrees of freedom
## Multiple R-squared: 0.5056, Adjusted R-squared: 0.3958
## F-statistic: 4.602 on 2 and 9 DF, p-value: 0.042So we can see the lm() function did not derive a coefficient for the time = 35 factor level. In this call the intercept is interpreted as and the other factor levels are all evaluated relative to this intercept:
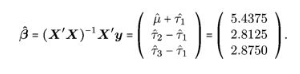
Obviously from this equation it’s easy to derive e.g. by adding the 1st and second coefficients together…
Hypothesis test for No Treatment Effect
Now let’s test if the treatment (changing the time factor) has any affect on the response variable (the height of the baked bread):
bread_example %>% aov(formula = height~time) %>% summary## Df Sum Sq Mean Sq F value Pr(>F)
## time 2 21.57 10.786 4.602 0.042 *
## Residuals 9 21.09 2.344
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1So we can see that the p-value here is the same as the p-value in the lm() summary and since it is < 0.05 we can safely reject and say different time factor levels had a significant impact on the response variable height.
Verify linearity assumption
Of course, using a lm() model assumes linearity and we should validate this assumed relationship between time and height:
Assumptions validation function
Validate_assumptions <- function(df, formula_ = NULL, model, factor, response) {
qq_plot <-
df %>%
ggplot(aes(sample = model %>% residuals))+
stat_qq()+
ggtitle("QQ plot of residuals")+
xlab("")+
ylab("")
Res_fac <- df %>%
ggplot()+
geom_point(aes(y = model %>% residuals(), x = df[,factor] ))+
ggtitle("Residuals VS factor levels") +
xlab("Residuals")+
ylab("Factor levels")
Res_fit <- df %>%
ggplot(aes(y = model %>% residuals(), x = model %>% predict))+
geom_point()+
ggtitle("Residuals VS fitted")+
xlab("Residuals")+
ylab("fitted")
Res_eu <- df %>%
ggplot(aes(y = model %>% residuals(), x = seq(nrow(df))))+
geom_point()+
ggtitle("Residuals VS experimental unit")+
xlab("Residuals")+
ylab("Experimental unit")
multiplot <- function(..., plotlist=NULL, file, cols=1, layout=NULL) {
library(grid)
# Make a list from the ... arguments and plotlist
plots <- c(list(...), plotlist)
numPlots = length(plots)
# If layout is NULL, then use 'cols' to determine layout
if (is.null(layout)) {
# Make the panel
# ncol: Number of columns of plots
# nrow: Number of rows needed, calculated from # of cols
layout <- matrix(seq(1, cols * ceiling(numPlots/cols)),
ncol = cols, nrow = ceiling(numPlots/cols))
}
if (numPlots==1) {
print(plots[[1]])
} else {
# Set up the page
grid.newpage()
pushViewport(viewport(layout = grid.layout(nrow(layout), ncol(layout))))
# Make each plot, in the correct location
for (i in 1:numPlots) {
# Get the i,j matrix positions of the regions that contain this subplot
matchidx <- as.data.frame(which(layout == i, arr.ind = TRUE))
print(plots[[i]], vp = viewport(layout.pos.row = matchidx$row,
layout.pos.col = matchidx$col))
}
}
}
multiplot(qq_plot, Res_fac, Res_fit, Res_eu, cols=2)
}
Validate_assumptions(df = bread_example,model = bread_example %>% lm(formula = height~time), factor = "time") 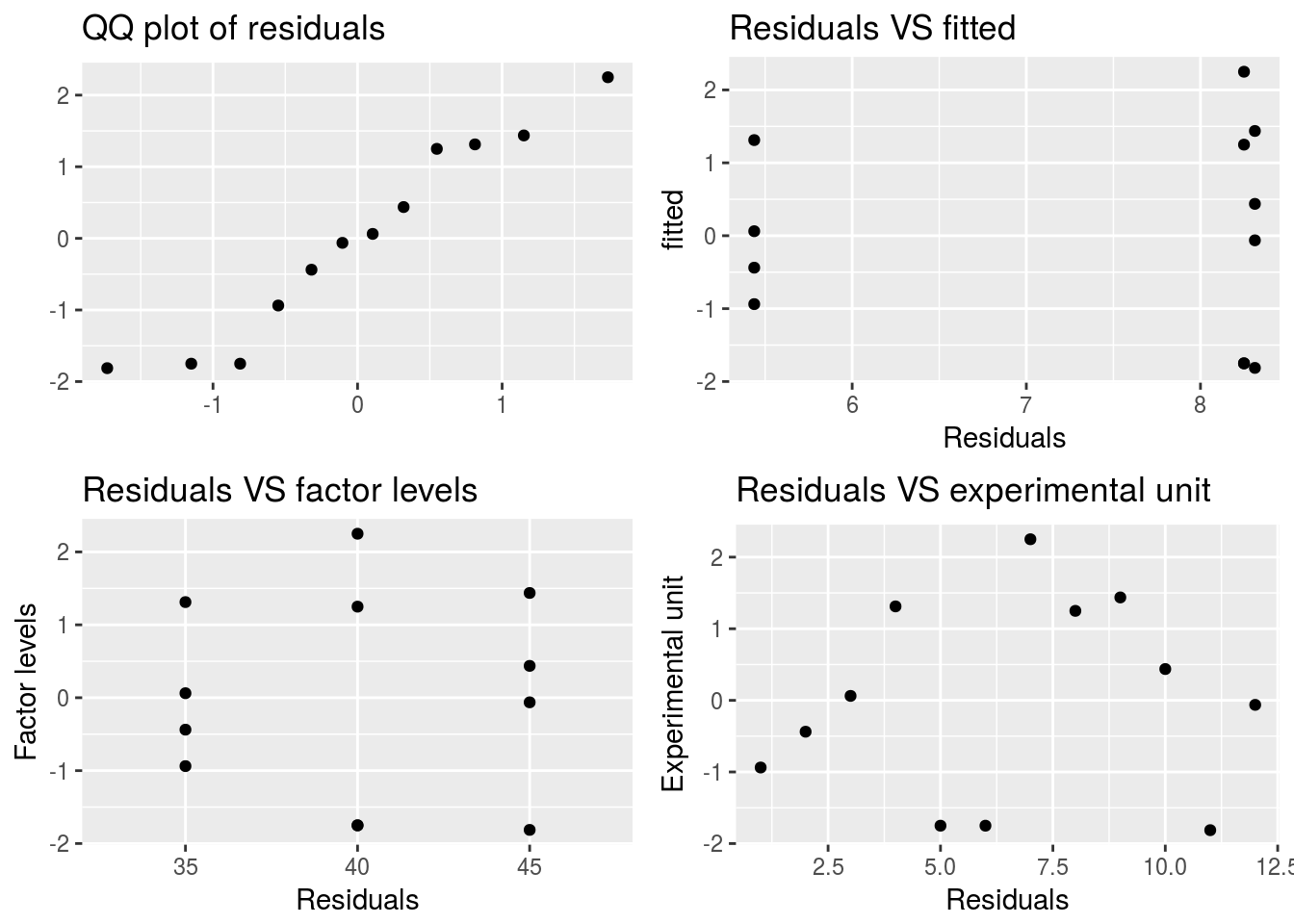
# qqnorm(y = bread_example %>% lm(formula = height~time) %>% residuals)In this case we do seem to have a fairly normal response relationship but with some variability in the lower corner. Consider that we only have 12 points.
A more serious violation of assumption is heterogeneity of variances. In general when the linearity assumption is violated so will the homogeniety of variances assumption. To remedy this we can apply a transformation to the data to reconsile the linearity assumption.
Box-Cox Power Transformations
** When variation is relative to the mean observation within each treatment **
This transformation will change the data so that it is distributed normally. Normally distributed data has honogeneous variances
These transformations ensure that
To find we can do:
box_cox <- boxcox(aov(bread_example,formula = height~time))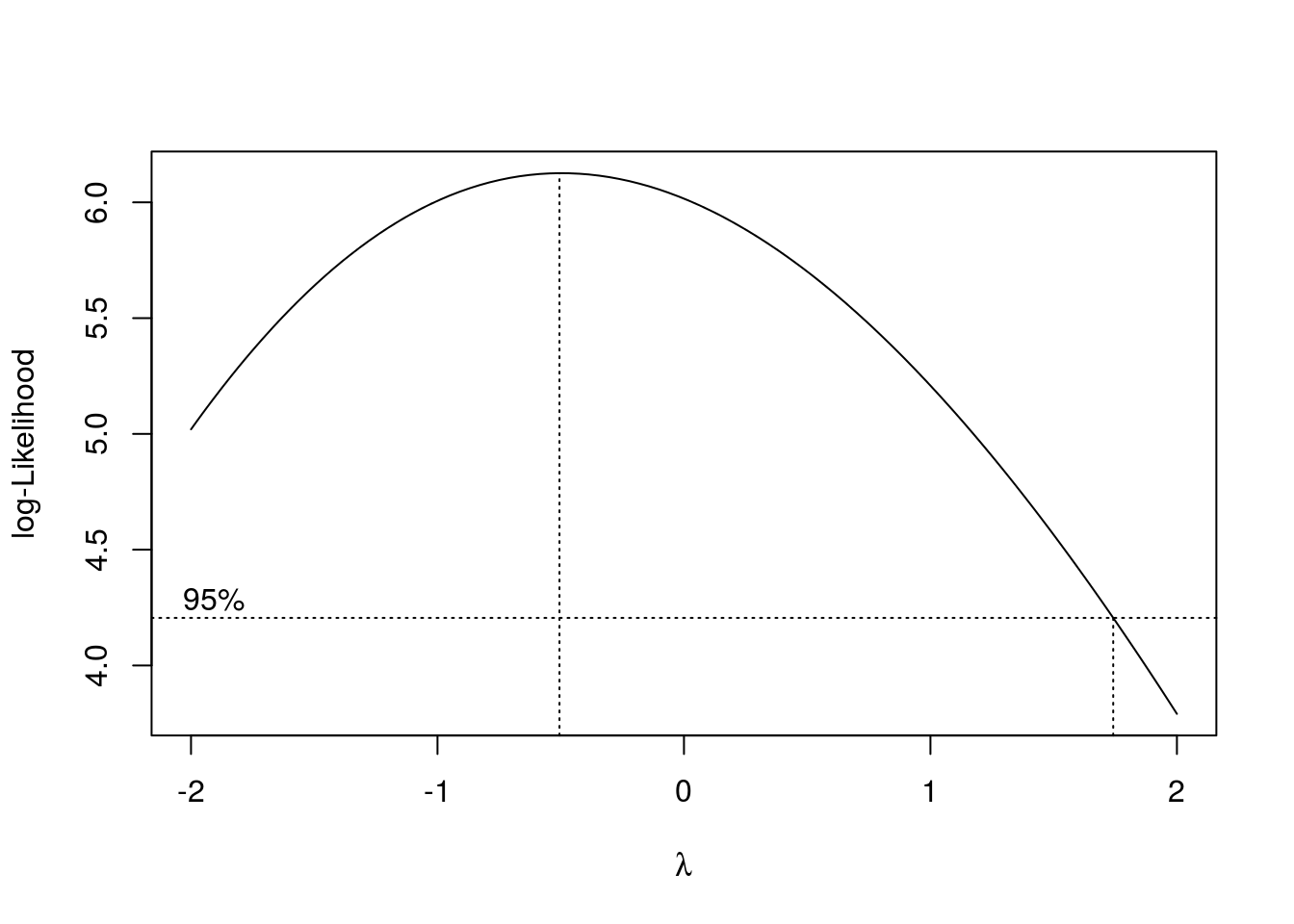
lambda = box_cox$x[which(box_cox$y == box_cox$y %>% max)]
lambda## [1] -0.5050505Now we transform the data:
bread_example_transformed <-
bread_example %>%
mutate(height = height^lambda)Let’s redo the normality validation on residuals:
qqnorm(y = bread_example_transformed %>% lm(formula = height~time) %>% residuals())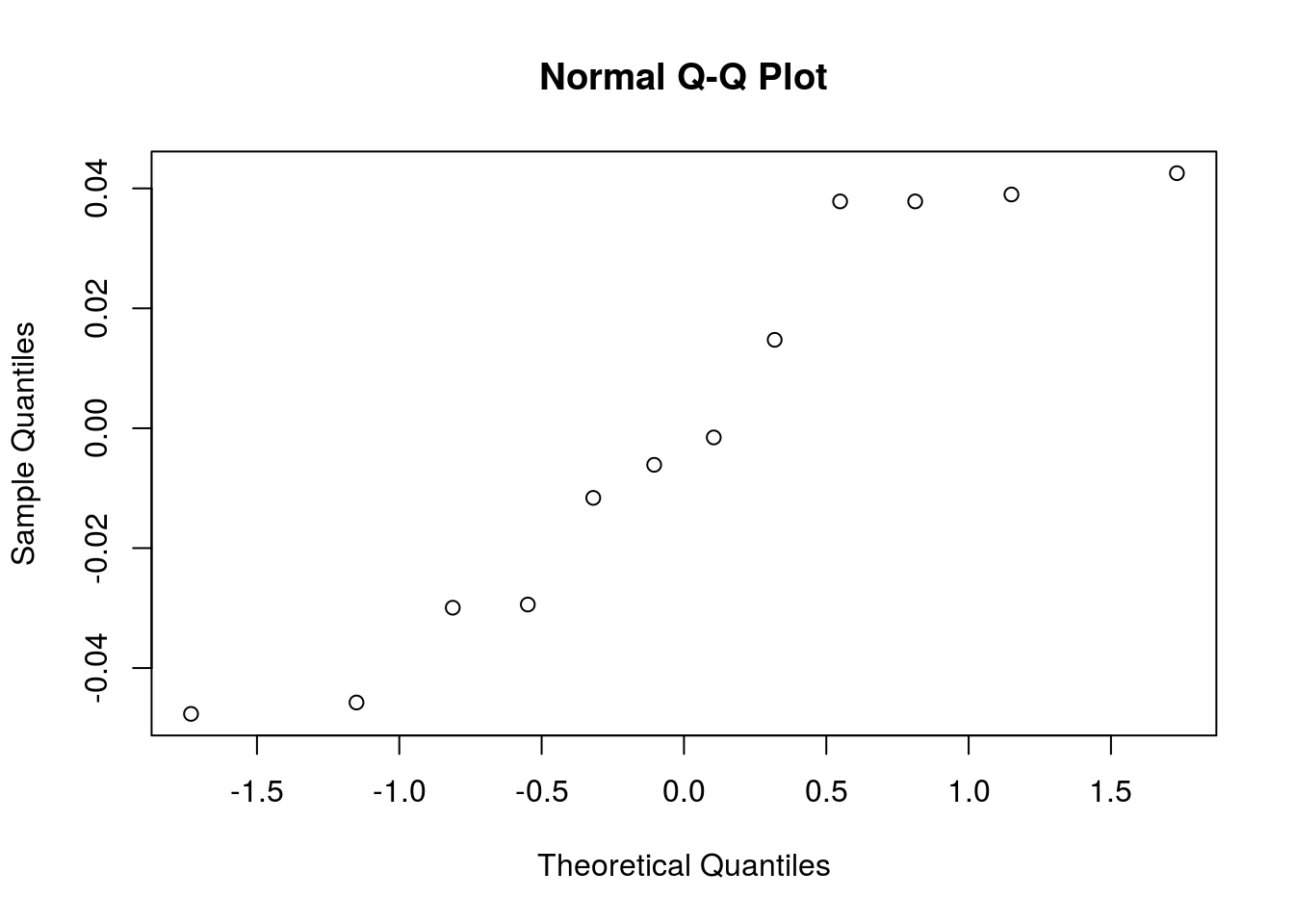
And if we look at the hypothesis test with the now normally distributed data:
bread_example_transformed %>% aov(formula = height~time) %>% summary## Df Sum Sq Mean Sq F value Pr(>F)
## time 2 0.01732 0.008662 6.134 0.0209 *
## Residuals 9 0.01271 0.001412
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Our new p-value is smaller which indicates that an observation as or more extreme than what we have is even more unlikely under the null hypothesis that there is no treatment effect.
Distributional transformations
** When variation is relative to the mean observation within each treatment **
An alternative to box-cox power transformation
OK, well let’s use the lognormal transformation and see the effect on the anova:
bread_example_lognormal <-
bread_example %>%
mutate(height = log(height))Let’s redo the normality validation on residuals:
qqnorm(y = bread_example_lognormal %>% lm(formula = height~time) %>% residuals())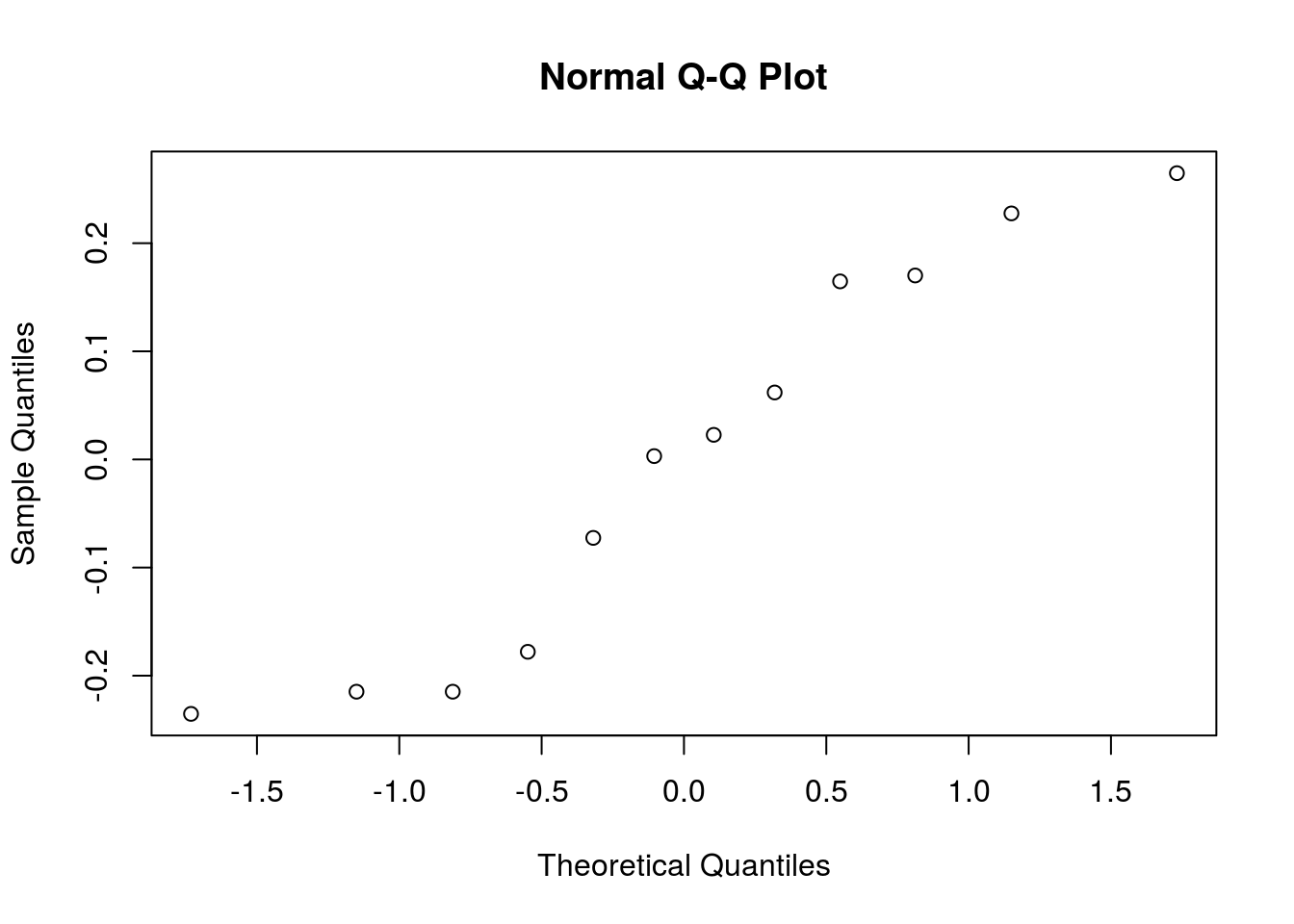
In this case we seem to fit the tail distribution better…
And if we look at the hypothesis test with the now more? normally distributed errors:
bread_example_lognormal %>% aov(formula = height~time) %>% summary## Df Sum Sq Mean Sq F value Pr(>F)
## time 2 0.4598 0.22992 5.64 0.0258 *
## Residuals 9 0.3669 0.04077
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The p-value is again shifted towards 0.0258 which indicates with higher certainty that we reject the null hypothesis
Alternatives to least squares regression
Weighted linear model
When we believe the heterogeneous variances are not related to the treatment mean we can use a weighted least squares
Use sd() as weights within treatments:
bread_example_Weighted <-
bread_example %>%
group_by(time) %>%
mutate(sd_treatment = 1/sd(height))
bread_example_Weighted## # A tibble: 12 x 4
## # Groups: time [3]
## loaf time height sd_treatment
## <dbl> <fct> <dbl> <dbl>
## 1 1.00 35 4.50 1.04
## 2 2.00 35 5.00 1.04
## 3 3.00 35 5.50 1.04
## 4 4.00 35 6.75 1.04
## 5 5.00 40 6.50 0.485
## 6 6.00 40 6.50 0.485
## 7 7.00 40 10.5 0.485
## 8 8.00 40 9.50 0.485
## 9 9.00 45 9.75 0.735
## 10 10.0 45 8.75 0.735
## 11 11.0 45 6.50 0.735
## 12 12.0 45 8.25 0.735Now that we have the weights for each treatment we can use it in a weighted OLS:
bread_example_Weighted %>% lm(formula = height~time,weights = bread_example_Weighted$sd_treatment) %>% summary##
## Call:
## lm(formula = height ~ time, data = ., weights = bread_example_Weighted$sd_treatment)
##
## Weighted Residuals:
## Min 1Q Median 3Q Max
## -1.5543 -1.0203 0.0050 0.9611 1.5671
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 5.4375 0.5941 9.152 7.44e-06 ***
## time40 2.8125 1.0520 2.674 0.0255 *
## time45 2.8750 0.9220 3.118 0.0124 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.209 on 9 degrees of freedom
## Multiple R-squared: 0.5805, Adjusted R-squared: 0.4872
## F-statistic: 6.226 on 2 and 9 DF, p-value: 0.02006This gives us a p-value of 0.02006 which is very similar to the other transformed methods
Creating a weighted OLS function
So to generalize this for simple case of CRD:
weighted_ols_anova <- function(df, formula_, factor, response) {
factor_enq <- dplyr::enquo(factor)
response_enq <- dplyr::enquo(response)
# factor_quo <- dplyr::quo(factor)
# response_quo <- dplyr::quo(response)
df <-
df %>%
group_by(!!factor_enq) %>%
mutate(sd_treatment = 1/sd(!!response_enq)) %>%
ungroup
# y = df %>% select(!!response_enq) %>% flatten_dbl
# x = df %>% select(!!factor_enq) %>% flatten_dbl
df %>% lm(formula = formula_, weights = sd_treatment) %>% anova
# df %>% lm(y = y, x = x, weights = sd_treatment) %>% anova
# return(df)
}
weighted_ols_anova(bread,height~time,time,height)## Analysis of Variance Table
##
## Response: height
## Df Sum Sq Mean Sq F value Pr(>F)
## time 2 18.209 9.1047 6.2263 0.02006 *
## Residuals 9 13.161 1.4623
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Generalized linear models
Pol data using logistic link function assuming multinomial distribution
Participants were asked to rank a treatment from 1 to 5
Data:
mod_full <- MASS::polr(data = daewr::teach,
formula = score ~ method,
weight = count)
mod_reduced <- MASS::polr(data = daewr::teach,
formula = score ~ 1,
weight = count)
anova(mod_full,mod_reduced)## Likelihood ratio tests of ordinal regression models
##
## Response: score
## Model Resid. df Resid. Dev Test Df LR stat. Pr(Chi)
## 1 1 294 885.9465
## 2 method 292 876.2986 1 vs 2 2 9.64787 0.008035108The reduced model predicts assuming only a global mean which conceptually means:
This shows that using different methods does make a difference compared to no particular method used. Because the p-value here rejects the null hypothesis that the two models are the same and therefore rejects the null hypothesis that all treatment effects are the same:
How do we measure treatment effect?
Let’s visualize the scores by method used
# Predicted <-
# daewr::teach %>%
# mutate(predicted_score = mod_full %>% predict)
# Predicted %>%
# group_by(method) %>%
# nest %>%
# mutate(Histogram = data %>% map(~hist(.$score))) %>%
# .Histogram
daewr::teach %>%
ggplot()+
geom_bar(aes(x = score,y = count),stat = "identity")+
facet_wrap(~method)+
ggtitle("Distribution of scores by method",subtitle = "Method 3 appears to outperform")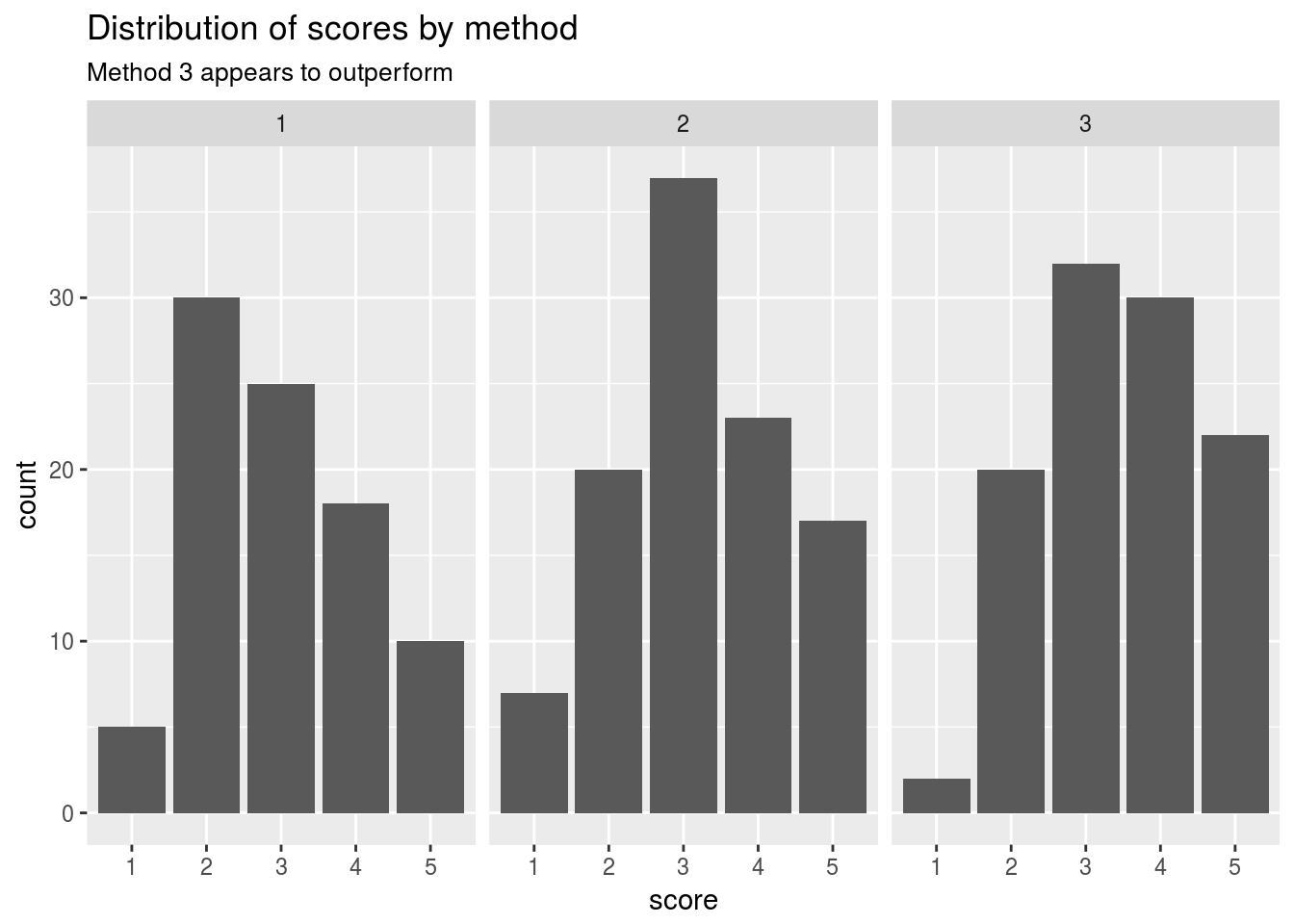
daewr::teach %>%
mutate_if(is.factor,as.numeric) %>%
group_by(method) %>%
summarise(mean_score = sum(score*count)/sum(count),
Total_votes = sum(count))## # A tibble: 3 x 3
## method mean_score Total_votes
## <dbl> <dbl> <dbl>
## 1 1.00 2.98 88.0
## 2 2.00 3.22 104
## 3 3.00 3.47 106We can see that on average the 3rd treatment here would outperform the rest of the treatment groups from this designed experiment.
Test for assumption violations
We can’t repeat the usual battery of tests here since we are dealing with a categorical response and the idea of residual error should be defined differently from say .
In order to run the usual battery of validity tests we need the residuals of the fitted model. However, this is a categorical response experiment.
# Validate_assumptions(df = daewr::teach, model = mod_full)Deternining the number of replicates
Bread dough experiment
The idea of practical difference is important here. If the practitioner wants to monitor any difference in cell means larger than say 3 inches he would use the Fpower1 function with .
Fpower1 calculates the power of the 1 way anova F distribution
Now we specify the number of replications we would like to calculate the power for given we know the variance of the experimental error
If we assume the naive OLS this value is:
daewr::bread %>% lm(formula = height~time) %>% residuals() %>% var## [1] 1.917614Let’s assume the value
power <- Fpower1(alpha = rep(0.05, 6-2+1),
nlev = 3,
nreps = 2:6,
Delta = 3,
sigma = sqrt(1.917614)
)
power## alpha nlev nreps Delta sigma power
## [1,] 0.05 3 2 3 1.384779 0.2086501
## [2,] 0.05 3 3 3 1.384779 0.4366902
## [3,] 0.05 3 4 3 1.384779 0.6315614
## [4,] 0.05 3 5 3 1.384779 0.7730600
## [5,] 0.05 3 6 3 1.384779 0.8666144This table then shows us that with as many as 6 replicates per treatment we can detect with ~87% accuracy a cell mean shift of 3 inches.
Based on the affordability in terms of time and money we can limit the factor under investigation using screening designs and perhaps limit the number of factors such that we get enough power out of the affordable number of replications.
Choosing optimal treatments
In general it is possible to construct hypothesis tests of comparisons before the design of experiments is carried out and responses are recorded but we will not focus on that here.
Instead we will assume the practitioner is interested in comparing treatments to one another in an unbiased way or compared to the current control treatment being used.
Unplanned Comparisons
When comparing specific treatments with one another after the experiment has been designed and carried out we must adjust for bias.
In R we can use the TukeyHSD function to compare cell mean shifts between different treatments
Sugarbeet dataset
This dataset is another CRD design. Let’s illustrate the TukeyHSD function here:
Sugerbeet_anova <- aov(yield ~ treat, data = daewr::sugarbeet)
Sugerbeet_anova## Call:
## aov(formula = yield ~ treat, data = daewr::sugarbeet)
##
## Terms:
## treat Residuals
## Sum of Squares 291.0050 29.5865
## Deg. of Freedom 3 14
##
## Residual standard error: 1.453727
## Estimated effects may be unbalancedSugerbeet_TukeyHSD <- TukeyHSD(Sugerbeet_anova, ordered = TRUE)
Sugerbeet_TukeyHSD## Tukey multiple comparisons of means
## 95% family-wise confidence level
## factor levels have been ordered
##
## Fit: aov(formula = yield ~ treat, data = daewr::sugarbeet)
##
## $treat
## diff lwr upr p adj
## B-A 6.3 3.3122236 9.287776 0.0001366
## D-A 10.0 7.1655464 12.834454 0.0000004
## C-A 10.1 7.2655464 12.934454 0.0000003
## D-B 3.7 0.8655464 6.534454 0.0094231
## C-B 3.8 0.9655464 6.634454 0.0077551
## C-D 0.1 -2.5723484 2.772348 0.9995162Here we can see that treatments C and D do not reject the null hypothesis that they have different cell means. However, the test also shows that no other treatments are considered the same and all reject at 5%.
Based purely on the confidence interval showed we could conclude that treatments C and D appear to be the most optimal if a higher mean in the response was required.
This function does not explicitly tell us what those means are, merely their differences.
Another, more conservative, function we can use is the SNK.test function from the agricolae package:
Sugarbeet_SNK <- SNK.test(Sugerbeet_anova, "treat", alpha = 0.05)
Sugerbeet_anova## Call:
## aov(formula = yield ~ treat, data = daewr::sugarbeet)
##
## Terms:
## treat Residuals
## Sum of Squares 291.0050 29.5865
## Deg. of Freedom 3 14
##
## Residual standard error: 1.453727
## Estimated effects may be unbalancedThis time we can clearly see the treatment means along with their summary statistics. As for rejection of the null hypothesis we can compare the M column in the groups output. Treatments that did not reject the null would have the same letters here.
Comparison to the current control treatment
To compare different treatments to the current control treatment we can use the function glht from the multcomp package
The glht function assumes that the 1st factor level is in fact the control treatment
Sugarbeet_glht <- glht(Sugerbeet_anova,linfct = mcp(treat = "Dunnett"), alternative = "greater")
Sugarbeet_glht %>% summary##
## Simultaneous Tests for General Linear Hypotheses
##
## Multiple Comparisons of Means: Dunnett Contrasts
##
##
## Fit: aov(formula = yield ~ treat, data = daewr::sugarbeet)
##
## Linear Hypotheses:
## Estimate Std. Error t value Pr(>t)
## B - A <= 0 6.3000 1.0279 6.129 <1e-04 ***
## C - A <= 0 10.1000 0.9752 10.357 <1e-04 ***
## D - A <= 0 10.0000 0.9752 10.254 <1e-04 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## (Adjusted p values reported -- single-step method)By specifying alternative = "greater" we can test the null hypothesis of the cell mean being greater than that of the control treatment using the Dunnett method.
Here we can again see that treatments C and D are superior to the control treatment A.