
Two Functions for Working with Amps
Working with the AMPS dataset
On one of my recent projects, I’ve had to do a lot of work with AMPS, drawing the data from the SQL database directly rather than via the portal on our website. Now, if you’ve never had to work with the AMPS data directly, its… tricky. I ended up writing some helpful functions that I thought I would blog about so the next person using the dataset can have an easier time.
Understanding the data
The data itself sits in a nice view on SQL with a grain of respondent (so each row contains all the responses for one respondent to the survey), however its the way the columns themselves are encoded that are the source of issue. Lets take a look!
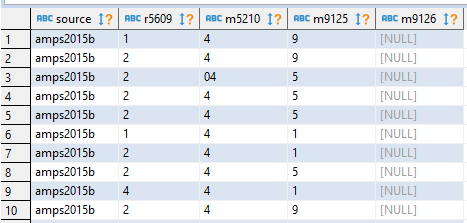
Raw AMPS data
As you can see, the column names aren’t really informative. Also, all the data is all encoded using numerical symbols. Fortunately, we have a translation-table that can be used to decode the data.
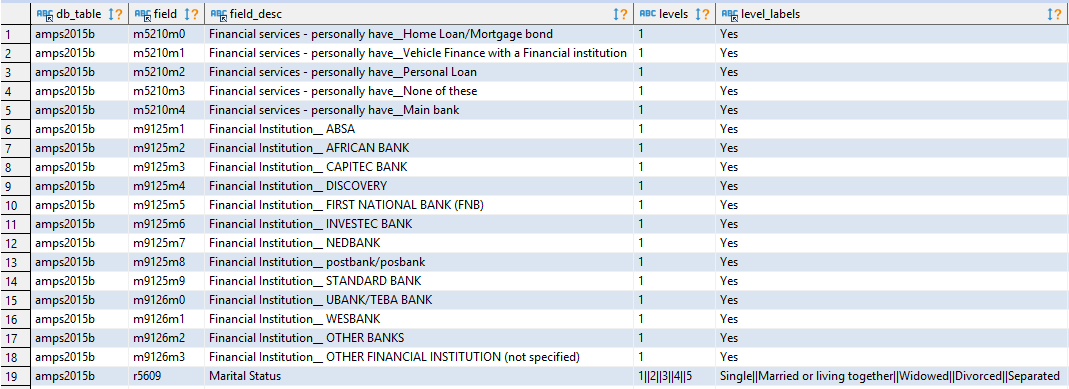
AMPS translation table
OK, lets describe whats going on here. The AMPS survey has two types of questions.
- Select 1 answer (eg: marital status)
- Choose all applicable answers (eg: What Financial Products do you own?)
In an online survey, we would use a Radio-button and a Checkbox respectively to capture these responses so I’m going to lean on this terminology going forward.
Getting back to the data, columns m5210, m9125 and m9126 all seem to be checkboxes while column r5609 seems to be a radio-button. This explains why m5210 has and entries “04” and “14” in the AMPS dataset - it means these respondents selected both checkbox both 0 and 4 or 1 and 4 for this question.
Getting back to the translation table we make the following observations:
- The column field always contains the corresponding column-name from AMPS
- The column field may contain the checkbox reference if the data came from a checkbox
- Field_desc always contains the descriptive column_name for the question asked
- Field_desc may contain the checkbox descriptive label
- Level_labels contains the labels for a radio-button corresponding to the levels column
- If there are more than 10 options for a checkbox (or possibly radio-button?), a new column is created. Thus columns m9125 and m9126 actually contain data for the same question!
Cool, I think we have a good grasp of what the data now. The next question is how do we want to transform the data to make it usable in R?
Well, radio-buttons just capture categorical data, so converting that column into a factor makes a lot of sense - we just need to tie the correct labels to the correct levels. For the checkboxes, we’ll need to one-hot encode the data since multiple options can be selected simultaneously. It makes a lot of sense to write a nice generic function that could be used to fix any of these columns. So that’s what I did :). The rest of this post will be showing off those functions.
One last note, There are some inconsistencies in the labelling between AMPS surveys. So the label for field m9125m7 might be different in amps2015b compared to amps2014b. While I’m at it. I’m going to ensure that the functions I write can handle this as well.
Working with AMPS in R
Read in Libraries
knitr::opts_chunk$set(echo = TRUE)
library(odbc)
library(EightyR)
load_toolbox()## -------------------------------------------
## Loading the Analytics Toolbox libary
## -------------------------------------------
##
## purrr
##
## ggplot2
##
## dplyr
##
## tidyr
##
## readr
##
## lubridate
##
## openxlsxRead in Data
It’ll help with writing the functions if I have the data already in R so I can play with it while I code. This is pretty straight-forward and so I’ll do it without comment. I bring in results from two different survey years, so I’m forced to address this while I write my functions.
con <- dbConnect(odbc::odbc(), "AMPS")
amps_query<-c("
select
'amps2015b' as source,
r5609,
r5235,
m5210,
m9125,
m9126
from amps.amps2015b
union all
select
'amps2014b' as source,
r5609,
r5235,
m5210,
m9125,
m9126
from amps.amps2014b
")
translate_query<-c("
select
db_table,
field,
field_desc,
levels,
level_labels,
ordinal
from eighty20_databaseadmin.translation_db
where db_table in ('amps2015b', 'amps2014b')
and
(
field like ('r5609%') or
field like ('r5235%') or
field like ('m5210%') or
field like ('m9125%') or
field like ('m9126%')
)
")
df.amps<- dplyr::tbl(con, sql(amps_query)) %>% collect()
df.translate<-dplyr::tbl(con, sql(translate_query))%>%collect()Lets take a quick glimpse at the AMPS
glimpse(df.amps)## Observations: 51,168
## Variables: 6
## $ source <chr> "amps2015b", "amps2015b", "amps2015b", "amps2015b", "am...
## $ r5609 <chr> "1", "2", "2", "2", "2", "1", "2", "2", "4", "2", "2", ...
## $ r5235 <chr> "9", "9", "5", "5", "5", "1", "1", "5", "1", "9", "1", ...
## $ m5210 <chr> "4", "4", "04", "4", "4", "4", "4", "4", "4", "4", "4",...
## $ m9125 <chr> "9", "9", "5", "5", "5", "1", "1", "5", "1", "9", "1", ...
## $ m9126 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,...a now the translation-table.
glimpse(df.translate)## Observations: 40
## Variables: 6
## $ db_table <chr> "amps2014b", "amps2015b", "amps2014b", "amps2015b...
## $ field <chr> "m5210m0", "m5210m0", "m5210m1", "m5210m1", "m521...
## $ field_desc <chr> "Financial services - personally have__Home Loan/...
## $ levels <chr> "1", "1", "1", "1", "1", "1", "1", "1", "1", "1",...
## $ level_labels <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", ...
## $ ordinal <chr> "N", "N", "N", "N", "N", "N", "N", "N", "N", "N",...Transforming Checkboxes
Now lets deal with the checkboxes. Again, I’m going to write a function to handle a single column, then create a wrapper function that allows for specifying multiple columns all at once.
fn_extract_one_checkbox <-
function(column, db_table, amps, translation) {
#first, only get rows relating to the field in consideration
src<-amps[[db_table]][1]
df.trans<-translation%>%
filter(grepl(column, field))%>%
filter(db_table==src)%>%
mutate(factor_level = substr(field, 7,7))
#strip out column_name
field_name <- gsub(" ","",strsplit(df.trans$field_desc[1],split = "_")[[1]][1])
#strip out verbose descriptions of factor levels
df.trans$factor_name<-sapply(strsplit(df.trans$field_desc,split = "_"), '[',3)
#initialise matrix to expand factors into
df.output_matrix<-setNames(data.frame(matrix(ncol = nrow(df.trans), nrow = nrow(amps), data = 0)), df.trans$factor_level)
#for each factor level, check whether that string occurs inside the data.
#NOTE: if more than 10 levels in a column, this would bug out.
lapply(names(df.output_matrix), function(lvl) {
df.output_matrix[[lvl]]<<-grepl(lvl,amps[[column]])
return(lvl)
})
#format names to be general_desc_factor_name
names(df.output_matrix)<-gsub("[[:space:]]","",tolower(df.trans$field_desc))
names(df.output_matrix)<-gsub("-","",names(df.output_matrix))
return(df.output_matrix)
}Checking the output,
checkbox<-fn_extract_one_checkbox("m5210", 'source', df.amps, df.translate)
glimpse(checkbox)## Observations: 51,168
## Variables: 5
## $ `financialservicespersonallyhave__homeloan/mortgagebond` <lgl> ...
## $ financialservicespersonallyhave__vehiclefinancewithafinancialinstitution <lgl> ...
## $ financialservicespersonallyhave__personalloan <lgl> ...
## $ financialservicespersonallyhave__noneofthese <lgl> ...
## $ financialservicespersonallyhave__mainbank <lgl> ...And now, creating a wrapper,
rm(fn_extract_one_checkbox)
fn_extract_checkboxes<-function(columns, db_table, amps, translation) {
fn_extract_one_checkbox<- function(column,db_table,amps) {
#first, only get rows relating to the field in consideration
src<-amps[[db_table]][1]
df.trans<-translation%>%
filter(grepl(column, field))%>%
filter(db_table==src)%>%
mutate(factor_level = substr(field, 7,7))
#strip out column_name
field_name <- gsub(" ","",strsplit(df.trans$field_desc[1],split = "_")[[1]][1])
#strip out verbose descriptions of factor levels
df.trans$factor_name<-sapply(strsplit(df.trans$field_desc,split = "_"), '[',3)
#initialise matrix to expand factors into
df.output_matrix<-setNames(data.frame(matrix(ncol = nrow(df.trans), nrow = nrow(amps), data = 0)), df.trans$factor_level)
#for each factor level, check whether that string occurs inside the data.
#NOTE: if more than 10 levels in a column, this would bug out.
lapply(names(df.output_matrix), function(lvl) {
df.output_matrix[[lvl]]<<-grepl(lvl,amps[[column]])
return(lvl)
})
#format names to be general_desc_factor_name
names(df.output_matrix)<-gsub("[[:space:]]","",tolower(df.trans$field_desc))
names(df.output_matrix)<-gsub("-","",names(df.output_matrix))
return(df.output_matrix)
}
return(
do.call('bind_rows',
lapply(split(amps, f = as.factor(amps[[db_table]])), function(amps) {
do.call('cbind',lapply(columns, FUN = fn_extract_one_checkbox, db_table, amps))
}))
)
}checkboxes<-fn_extract_checkboxes(c("m5210", "m9125","m9126"), 'source', df.amps, df.translate)
glimpse(checkboxes)## Observations: 51,168
## Variables: 19
## $ `financialservicespersonallyhave__homeloan/mortgagebond` <lgl> ...
## $ financialservicespersonallyhave__vehiclefinancewithafinancialinstitution <lgl> ...
## $ financialservicespersonallyhave__personalloan <lgl> ...
## $ financialservicespersonallyhave__noneofthese <lgl> ...
## $ financialservicespersonallyhave__mainbank <lgl> ...
## $ financialinstitution__absa <lgl> ...
## $ financialinstitution__africanbank <lgl> ...
## $ financialinstitution__capitecbank <lgl> ...
## $ financialinstitution__discovery <lgl> ...
## $ `financialinstitution__firstnationalbank(fnb)` <lgl> ...
## $ financialinstitution__investecbank <lgl> ...
## $ financialinstitution__nedbank <lgl> ...
## $ `financialinstitution__postbank/posbank` <lgl> ...
## $ financialinstitution__standardbank <lgl> ...
## $ `financialinstitution__ubank/tebabank` <lgl> ...
## $ financialinstitution__wesbank <lgl> ...
## $ financialinstitution__otherbanks <lgl> ...
## $ `financialinstitution__other(notspecified)` <lgl> ...
## $ `financialinstitution__otherfinancialinstitution(notspecified)` <lgl> ...Nice! Its maybe worth noting that I’ve been a bit inconsistent in that I’ve removed white-space in the column_names, but I’ve been happy to leave in brackets or dashes. I’m happy with this for now, but maybe later I’ll decide to either not handle whitespace at all, or to handle all characters that shouldn’t appear in a column name. Right now, the user can get rid of brackets if they want by using either gsub() or make.names.
Bringing it all together
Let’s create a final converted dataset using these functions just to show how easy it is. Lets have a look at the unformatted version again:
glimpse(df.amps)## Observations: 51,168
## Variables: 6
## $ source <chr> "amps2015b", "amps2015b", "amps2015b", "amps2015b", "am...
## $ r5609 <chr> "1", "2", "2", "2", "2", "1", "2", "2", "4", "2", "2", ...
## $ r5235 <chr> "9", "9", "5", "5", "5", "1", "1", "5", "1", "9", "1", ...
## $ m5210 <chr> "4", "4", "04", "4", "4", "4", "4", "4", "4", "4", "4",...
## $ m9125 <chr> "9", "9", "5", "5", "5", "1", "1", "5", "1", "9", "1", ...
## $ m9126 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,...and now the formatted version:
formatted_amps<-cbind(
fn_label_radio_buttons(c('r5609','r5235'), 'source',df.amps,df.translate),
fn_extract_checkboxes(c("m5210", "m9125","m9126"), 'source', df.amps, df.translate))## Warning in bind_rows_(x, .id): Unequal factor levels: coercing to character## Warning in bind_rows_(x, .id): binding character and factor vector,
## coercing into character vector
## Warning in bind_rows_(x, .id): binding character and factor vector,
## coercing into character vectorglimpse(formatted_amps)## Observations: 51,168
## Variables: 21
## $ marital_status <fct> ...
## $ main_bank_for_all_banking_transactions <chr> ...
## $ `financialservicespersonallyhave__homeloan/mortgagebond` <lgl> ...
## $ financialservicespersonallyhave__vehiclefinancewithafinancialinstitution <lgl> ...
## $ financialservicespersonallyhave__personalloan <lgl> ...
## $ financialservicespersonallyhave__noneofthese <lgl> ...
## $ financialservicespersonallyhave__mainbank <lgl> ...
## $ financialinstitution__absa <lgl> ...
## $ financialinstitution__africanbank <lgl> ...
## $ financialinstitution__capitecbank <lgl> ...
## $ financialinstitution__discovery <lgl> ...
## $ `financialinstitution__firstnationalbank(fnb)` <lgl> ...
## $ financialinstitution__investecbank <lgl> ...
## $ financialinstitution__nedbank <lgl> ...
## $ `financialinstitution__postbank/posbank` <lgl> ...
## $ financialinstitution__standardbank <lgl> ...
## $ `financialinstitution__ubank/tebabank` <lgl> ...
## $ financialinstitution__wesbank <lgl> ...
## $ financialinstitution__otherbanks <lgl> ...
## $ `financialinstitution__other(notspecified)` <lgl> ...
## $ `financialinstitution__otherfinancialinstitution(notspecified)` <lgl> ...Just like that, we’ve gone from some cryptic column-names with uninterpretable data, to something that can immediately be used for analytics!
Conclusions and Criticisms
The key takeout of this blog is that the functions fn_label_radio_buttons and fn_extract_checkboxes can be used to convert raw AMPS data into something that’s analytics-friendly in R. It account for different data labelling between versions of the AMPS survey as well.
One criticism of these functions on reflection, is I assume that the amps dataset contains a column corresponding to db_table in the translation table. This column doesn’t actually exist and it’s something I created myself in the SQL scripts, but I don’t see a way around it when working with multiple years of AMPS at once to figure out which entry in the translations table to use.
Another criticism is that, when the levels in different years of AMPS data don’t match exactly, those columns are coerced into character instead of factor. I could handle this a bit more explicitly to avoid this behaviour.
A piece of outstanding work is that I should write a wrapper for the radio and checkbox functions. Then the user could only call one function, specifying which columns are radio_buttons and which are checkboxes and the wrapper could handle each accordingly.